Warum ich einen Markdown-Editor gebaut habe: VMark
TL;DR
Ein Nicht-Programmierer begann im August 2025 mit Vibe-Coding und baute VMark — einen Markdown-Editor — in sechs Wochen. Wesentliche Erkenntnisse: Git ist unverzichtbar (es ist Ihre Rückgängig-Taste), TDD hält KI ehrlich (Tests sind Grenzen gegen Fehler), Sie denken im Vibe, Sie coden nicht im Vibe (KI erledigt die Arbeit, Sie treffen die Urteile), und modellübergreifende Diskussion schlägt einseitiges Vertrauen. Die Reise bewies, dass Nutzer Entwickler werden können — aber nur, wenn sie in einige grundlegende Fähigkeiten investieren.
Wie es begann
Ehrlich gesagt war der Bau von VMark für mich in erster Linie eine Lern- und Erfahrungsreise.
Ich begann am 17. August 2025 mit dem aufkommenden Programmiertrend, bekannt als Vibe Coding, zu experimentieren. Der Begriff Vibe Coding selbst wurde am 2. Februar 2025 zum ersten Mal geprägt und verbreitet, ausgehend von einem Beitrag von Andrej Karpathy auf X (ehemals Twitter).
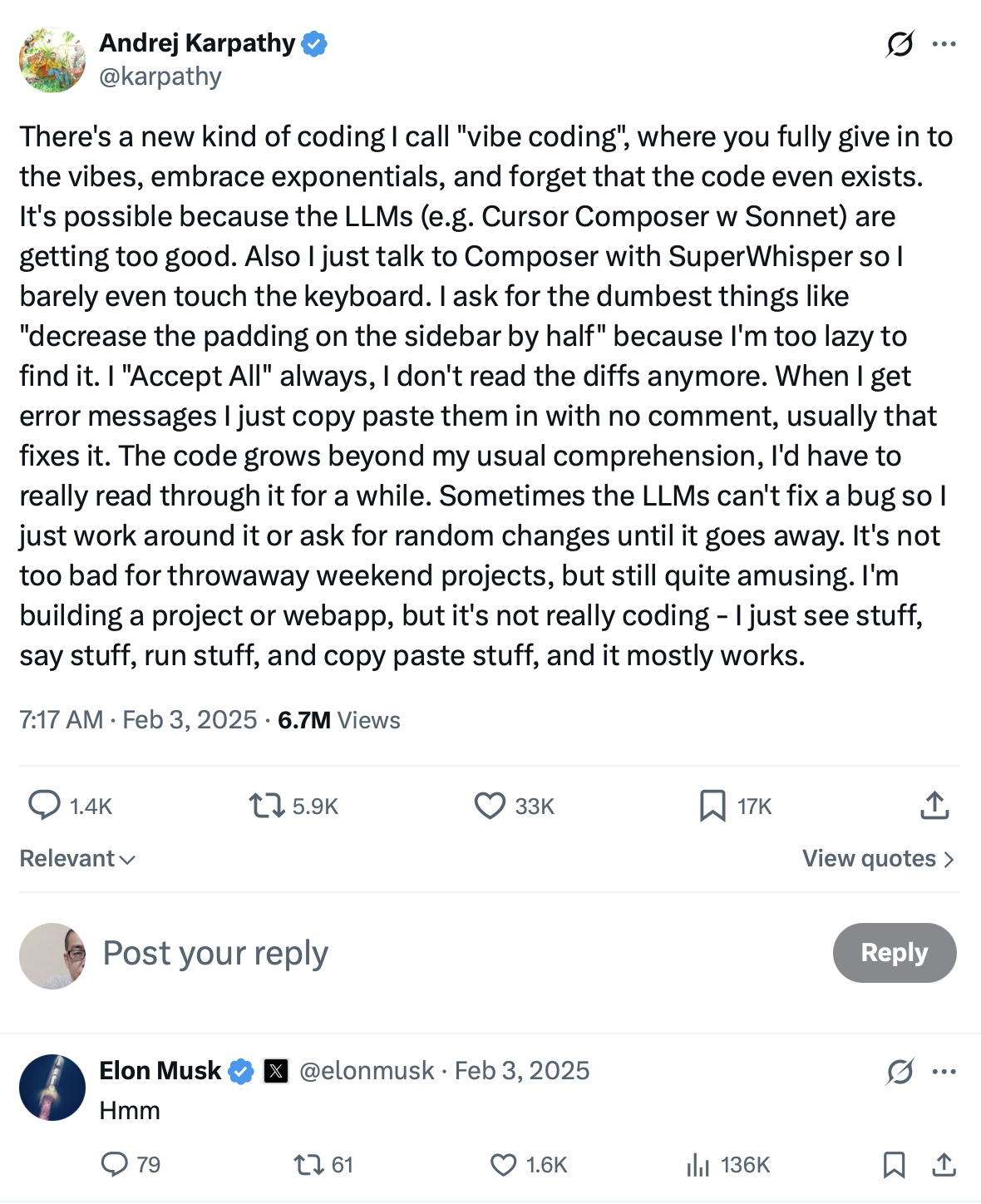
Andrej Karpathy ist ein äußerst einflussreicher Forscher und Pädagoge im Bereich maschinelles Lernen. Er hatte wichtige Positionen bei Unternehmen wie OpenAI und Tesla inne und gründete später Eureka Labs, mit Fokus auf KI-nativer Bildung. Sein Tweet führte nicht nur das Konzept des „Vibe Codings" ein, sondern verbreitete sich auch schnell in der Tech-Community und löste umfangreiche Folgediskussionen aus.
Als ich Vibe-Coding-Tools bemerkte und zu nutzen begann, war bereits fast ein halbes Jahr vergangen. Damals war Claude Code noch bei Version 1.0.82. Als ich dieses Dokument am 9. Februar 2026 schreibe, hat es Version 2.1.37 erreicht, mit 112 Versionsaktualisierungen dazwischen.
Ganz am Anfang nutzte ich diese Tools nur, um einige Automatisierungsskripte, die ich längst geschrieben hatte, zu verbessern — zum Beispiel das Batch-Übersetzen von E-Books. Was ich erkannte, war, dass ich nur bereits vorhandene Fähigkeiten verstärkte.
Wenn ich bereits wusste, wie man etwas tut, half mir KI, es besser zu tun. Wenn ich nicht wusste, wie man etwas tut, gab mir KI oft die Illusion, dass ich es könnte — normalerweise mit einem anfänglichen „Wow"-Moment — gefolgt von nichts. Was ich ursprünglich nicht konnte, konnte ich immer noch nicht. Diese schönen Bilder, auffälligen Videos und langen Artikel waren in vielen Fällen nur eine weitere Form von „Hello World" für eine neue Ära.[1]
Ich bin nicht völlig unwissend in der Programmierung, aber ich bin sicherlich kein echter Computertechniker. Bestenfalls bin ich ein Power-User unter gewöhnlichen Nutzern. Ich kenne etwas Code und habe sogar ein Buch über Python-Programmierung veröffentlicht. Aber das macht mich nicht zu einem Ingenieur. Es ist wie jemand, der eine Strohhütte bauen kann: Er weiß mehr als jemand, der es nicht kann, aber er ist nicht einmal annähernd in derselben Kategorie wie diejenigen, die Wolkenkratzer oder Brücken entwerfen.
Und dann änderte KI alles.
Von Skripten zu Software
Von Anfang an bis jetzt habe ich fast jede verfügbare KI-Coding-CLI ausprobiert: Claude Code, Codex CLI, Gemini CLI, sogar inoffizielle Tools wie Grok CLI, sowie Open-Source-Alternativen wie Aider. Dennoch war das, was ich am meisten verwendete, immer Claude Code. Nachdem Codex CLI einen MCP Server einführte, verwendete ich Claude Code sogar noch mehr, weil es Codex CLI direkt im interaktiven Modus aufrufen konnte. Ironischerweise bietet Claude Code, obwohl es das erste war, das MCP-Protokoll vorzuschlagen, selbst noch keinen MCP Server an (Stand 10.02.2026).
Zunächst fühlte sich Claude Code wie ein professioneller IT-Spezialist an, der plötzlich bei mir einzog — jemanden, den man normalerweise nur in großen Unternehmen findet. Alles Computerbezogene konnte übergeben werden. Es löste Probleme mit Befehlszeilen-Tools, die ich noch nie gesehen hatte, oder vertrauten Befehlen, die auf unbekannte Weise verwendet wurden.
Solange es ausreichende Berechtigungen erhielt, gab es fast nichts, was es nicht tun konnte: Systemwartung, Updates, Netzwerke, Bereitstellen von Software oder Diensten mit unzähligen kniffligen Konfigurationen und Konflikten. Eine solche Person könnte man niemals für 200 USD pro Monat einstellen.
Danach begann die Anzahl der Maschinen, die ich nutzte, zu steigen. Cloud-Instanzen wuchsen von ein oder zwei auf fünf oder sechs; Maschinen zu Hause stiegen von zwei oder drei auf sieben oder acht. Probleme, deren Einrichtung früher Tage dauerte — und oft wegen meines begrenzten Wissens scheiterte — verschwanden plötzlich. Claude Code übernahm alle Maschinenoperationen für mich, und nach dem Beheben von Problemen schrieb es sogar Auto-Start-Skripte, um sicherzustellen, dass dieselben Probleme nie wieder auftraten.
Dann begann ich Dinge zu schreiben, die ich zuvor nie schreiben konnte.
Zuerst kam eine Browser-Erweiterung namens Insidebar-ai, die den ständigen Kontextwechsel und das Kopieren und Einfügen im Browser reduzieren sollte. Dann kam Tepub, das tatsächlich wie echte Software aussah: ein Python-Befehlszeilen-Tool zum Übersetzen von EPUB-Büchern (einsprachig oder zweisprachig) und sogar zum Erzeugen von Hörbüchern. Davor hatte ich nur ungeschickte, handgeschriebene Python-Skripte.
Ich fühlte mich wie ein Modeblogger, der plötzlich Schneiderkenntnisse erworben hatte — oder sogar eine Textilfabrik besaß. Unabhängig davon, wie gut mein Geschmack einmal war, einmal habe ich unbeabsichtigt mehr über verwandte und grundlegende Bereiche gelernt, haben sich viele meiner Ansichten natürlich — und unvermeidlich — verändert.
Ich beschloss, mehrere Jahre damit zu verbringen, mich in einen echten Computertechniker zu verwandeln.
Ich hatte etwas Ähnliches zuvor getan. Ich habe viele Jahre lang Lesekurse bei New Oriental unterrichtet. Nach mehreren Jahren des Unterrichtens hatte ich mich, zumindest beim Lesen, effektiv in einen englischen Muttersprachler verwandelt (nicht Sprecher). Mein Sprechen war schrecklich — aber es gab dafür sowieso keine wirkliche Verwendung — also war das so.
Ich strebte nichts Großes an. Ich wollte nur mein Gehirn trainieren. Es ist das interessanteste Spiel, oder?
Ich beschloss, jede Woche ein relativ kleines Projekt abzuschließen und jeden Monat ein relativ größeres Projekt. Nach Dutzenden von Projekten dachte ich, ich würde eine andere Person sein.
Drei Monate später hatte ich mehr als ein Dutzend Projekte gebaut — einige scheiterten, einige wurden aufgegeben — aber alle waren faszinierend. Während dieses Prozesses wurde KI in einem erstaunlichen Tempo sichtbar intelligenter. Ohne intensive, praxisnahe Nutzung würde man das nie wirklich spüren; bestenfalls hört man davon aus zweiter Hand. Dieses Gefühl ist wichtig, denn es hat direkt eine KI-Philosophie geprägt, die ich später besprechen werde: eine feste Überzeugung, dass KI immer intelligenter werden wird.
Im November 2025 baute ich einen EPUB-Reader basierend auf foliate.js, genau so gestaltet, wie ich es mochte. Ich implementierte Funktionen, die ich auf Kindle oder Apple Books (macOS/iOS) nicht bekommen konnte: geschichtete Hervorhebungen, Verwaltung von Hervorhebungen und Notizen (nicht nur Export), benutzerdefinierte Wörterbücher, Exportieren von Obsidian-Karten und mehr. Es gab gelegentliche Fehler, aber sie beeinträchtigten meine persönliche Nutzung nicht.
Das heißt, ich war zu verlegen, um es öffentlich zu veröffentlichen. Die größte Lektion, die ich lernte, war diese: etwas, das nur für sich selbst gebaut wurde, ist ein Spielzeug; etwas, das für viele Menschen gebaut wurde, ist ein Produkt oder ein Service.
Warum ein Markdown-Editor
Natürlich dachte ich noch immer nur an meine eigenen Bedürfnisse. Einmal war „Lesen" gelöst, das Nächste, was ich für mich lösen konnte, war „Schreiben". Also begann ich am 27. Dezember 2025 — nach der Rückkehr nach Peking aus Harbin nach Weihnachten — mit dem Bau von VMark. Der Name bedeutet einfach Vibe-coded Markdown Editor. Sogar sein Symbol wurde vibe-kodiert: Claude Code instruierte Sketch über MCP, es zu zeichnen.
Die Wahl, einen Markdown-Editor zu bauen, hatte auch andere Gründe.
Ich hatte eine ziemlich klare Vorstellung davon, wie ein Markdown-Editor sein sollte.
Ich hatte auch viele unerfüllte Bedürfnisse, die bestehende Editoren nicht erfüllten.
Intuitiv fühlte es sich wie ein Projekt der richtigen Größe für mich in diesem Stadium an — ein „mittelgroßes" Projekt, das ich realistischerweise bewältigen konnte.
Ich glaubte auch, dass ein solches Projekt es KI ermöglichen würde, mir mehr zu helfen. Schließlich ist ein Markdown-Editor nichts Neues; jedes Detail davon versteht KI besser als fast jeder.
Und dann geriet ich in ein Loch — ein sehr tiefes. Ein wirklich guter Markdown-Editor ist extrem schwierig zu bauen, weit komplexer als ich mir vorgestellt hatte.
Ich war oberflächlich ein paar Tage glücklich, verbrachte dann eine Woche damit, wiederholt zu kämpfen und niedergeschlagen zu sein. Schließlich fragte ich ChatGPT:
Wie groß ist der Arbeitsaufwand für den Aufbau eines wirklich guten Markdown-Editors?
Die Eröffnung seiner Antwort ließ mich lachen — über meine eigene Unwissenheit.
Ein verwendbarer Markdown-Editor: 1 Person · 1–2 Wochen
Ein guter Markdown-Editor: 1–2 Personen · 1–3 Monate
Ein Markdown-Editor, auf den schwere Autoren nicht verzichten können:
3–8 Personen · 1–3 Jahre (und im Wesentlichen ein kontinuierlich weiterentwickeltes Projekt)(Viele Details ausgelassen.)
Dann kam die letzte Frage:
Wie lange sind Sie bereit, ihn zu pflegen (in Jahren, nicht Monaten)?
Das beruhigte mich tatsächlich. Pflege in Jahren gemessen? Das könnte für andere ein Problem sein, aber nicht für mich. Ich fürchte das nicht. Ich hatte auch eine kleine Erkenntnis: Markdown ist wahrscheinlich das grundlegendste Format für die zukünftige Mensch-Computer-Interaktion. Ich werde es nur mehr und mehr nutzen. Wenn dem so ist, warum es dann nicht auf unbestimmte Zeit pflegen?
Als Randbemerkung entdeckte ich während dieses Prozesses, dass Typora — ein Editor, den ich viele Jahre lang genutzt und mehrere Lizenzen für bezahlt hatte — tatsächlich von einem Unternehmen in Shanghai entwickelt wird.
Zwei Wochen später hatte VMark eine grundlegende Form. Einen vollen Monat später, am 27. Januar 2026, änderte ich sein Label von Alpha zu Beta.
Ein eigenwilliger Editor
VMark ist stark eigenwillig. Tatsächlich vermute ich, dass das für alle vibe-codierten Software und Dienste so sein wird. Das ist unvermeidlich, denn Vibe Coding ist von Natur aus ein Produktionsprozess ohne Meetings — nur ich und ein Ausführender, der nie widerspricht.
Hier sind einige meiner persönlichen Vorlieben:
Alle Nicht-Inhaltsinformationen müssen außerhalb des Hauptbereichs bleiben. Selbst das Formatierungsmenü wird unten platziert.
Ich habe hartnäckige typografische Vorlieben.
Chinesische Schriftzeichen müssen Abstände zwischen ihnen haben, aber eingebettete englische Buchstaben in chinesischem Text dürfen es nicht. Vor VMark erfüllte kein Editor diese Nischenanforderung, die kommerziell wertlos ist.
Zeilenabstand muss jederzeit anpassbar sein.
Tabellen sollten nur im Kopfzeilenfeld eine Hintergrundfarbe haben. Ich hasse Zebrastreifen.
Tabellen und Bilder sollten zentrierbar sein.
Nur H1-Überschriften sollten Unterstriche haben.
Einige Funktionen, die typischerweise nur in Code-Editoren zu finden sind, müssen vorhanden sein:
Mehrcursor-Modus
Mehrere Zeilen sortieren
Automatische Interpunktionspaarung
Andere sind optional, aber schön zu haben:
Tab-Rechts-Escape
Ich mag WYSIWYG-Markdown-Editoren, aber ich hasse es, ständig zwischen Ansichten zu wechseln (auch wenn es manchmal notwendig ist). Also entwarf ich eine Quellvorschau-Funktion (F5), mit der ich den Quellcode des aktuellen Blocks anzeigen und bearbeiten kann, ohne die gesamte Ansicht zu wechseln.
PDF exportieren ist nicht so wichtig. Dynamisches HTML exportieren ist es.
Und so weiter.
Fehler und Durchbrüche
Während der Entwicklung machte ich unzählige Fehler, einschließlich, aber nicht beschränkt auf:
Zu frühe Implementierung komplexer Funktionen, die den Umfang unnötig aufblähten
Zeit mit Funktionen verbringen, die später entfernt wurden
Zwischen Pfaden zögern, immer wieder neu starten
Einen Pfad zu lange verfolgen, bevor ich erkannte, dass mir Leitprinzipien fehlten
Kurz gesagt, ich machte jeden Fehler, den ein unreifer Ingenieur machen kann — viele Male. Ein Ergebnis war, dass ich von morgens bis abends fast ununterbrochen auf einen Bildschirm starrte. Schmerzhaft, und doch freudig.
Natürlich gab es Dinge, die ich richtig machte.
Zum Beispiel fügte ich VMark einen MCP Server hinzu, bevor seine Kernfunktionen überhaupt solide waren. Dies ermöglichte es KI, Inhalte direkt in den Editor zu senden. Ich konnte Claude Code im Terminal einfach bitten:
„Stellen Sie Markdown-Inhalt für das Testen dieser Funktion bereit, mit umfassender Abdeckung der Edge Cases."
Jedes Mal erstaunte mich der generierte Testinhalt — und sparte enorme Zeit und Energie.
Anfangs hatte ich keine Ahnung, was MCP wirklich war. Ich verstand es erst tief, nachdem ich einen MCP Server geklont und ihn in etwas völlig Unverwandtes mit VMark modifiziert hatte — was zu einem anderen Projekt namens CCCMemory führte. Vibe-Lernen, tatsächlich.
Im realen Einsatz ist MCP in einem Markdown-Editor unglaublich nützlich — besonders für das Zeichnen von Mermaid-Diagrammen. Niemand versteht diese besser als KI. Dasselbe gilt für reguläre Ausdrücke. Ich bitte KI jetzt routinemäßig, ihre Ausgabe — Analyseberichte, Auditberichte — direkt in VMark zu senden. Es ist weit angenehmer als sie in einem Terminal oder VSCode zu lesen.
Am 2. Februar 2026 — genau ein Jahr nach der Geburt des Vibe-Coding-Konzepts — fühlte ich, dass VMark zu einem Tool geworden war, das ich wirklich komfortabel nutzen konnte. Es hatte noch viele Fehler, aber ich hatte bereits begonnen, täglich damit zu schreiben und dabei Fehler zu beheben.
Ich fügte sogar ein Befehlszeilen-Panel und KI-Genies hinzu (ehrlich gesagt noch nicht sehr verwendbar, aufgrund der Eigenheiten verschiedener KI-Anbieter). Dennoch war es eindeutig auf einem Weg, auf dem es für mich immer besser wurde — und auf dem ich keine anderen Markdown-Editoren mehr nutzen konnte.
Git ist unverzichtbar
Sechs Wochen in fühlte ich, dass es einige Details gab, die es wert waren, mit anderen „Nicht-Ingenieuren" wie mir zu teilen.
Erstens: Obwohl ich kein echter Ingenieur bin, verstehe ich glücklicherweise grundlegende Git-Operationen. Ich habe Git viele Jahre lang verwendet, auch wenn es ein Tool zu sein scheint, das nur Ingenieure benutzen. Rückblickend denke ich, dass ich meinen GitHub-Account vor etwa 15 Jahren registriert habe.
Ich benutze selten fortgeschrittene Git-Funktionen. Zum Beispiel verwende ich keine Git-Worktrees, wie von Claude Code empfohlen. Stattdessen verwende ich zwei separate Maschinen. Ich verwende nur grundlegende Befehle, alle über natürlichsprachliche Anweisungen an Claude Code erteilt.
Alles passiert auf Branches. Ich experimentiere frei, dann sage ich:
„Fasse die bisher gewonnenen Erkenntnisse zusammen, setze den aktuellen Branch zurück und fangen wir von vorne an."
Ohne Git kann man einfach kein nicht-triviales Projekt durchführen. Dies ist besonders wichtig für Nicht-Programmierer: Das Erlernen grundlegender Git-Konzepte ist unverzichtbar. Man lernt automatisch mehr, nur indem man Claude Code bei der Arbeit zusieht.
Zweitens muss man den TDD-Workflow verstehen. Alles tun, um die Testabdeckung zu verbessern. Das Konzept der Tests als Grenzen verstehen. Fehler sind unvermeidlich — wie Kornkäfer in einem Getreidesilo. Ohne ausreichende Testabdeckung hat man keine Chance, sie zu finden.
Vibe-Denken, nicht Vibe-Coden
Hier ist das Kernphilosophieprinzip: Sie coden nicht im Vibe; Sie denken im Vibe. Produkte und Dienste sind immer das Ergebnis von Denken, nicht das unvermeidliche Ergebnis von Arbeit.
KI hat viel des „Tuens" übernommen, aber sie kann nur beim grundlegenden Denken von Was, Warum und Wie helfen. Die Gefahr ist, dass sie immer Ihrer Führung folgt. Wenn Sie sich auf sie zum Denken verlassen, wird sie Sie still in Ihren eigenen kognitiven Vorurteilen einfangen[2] — während Sie sich freier als je zuvor fühlen. Wie der Liedtext sagt:
„We are all just prisoners here, of our own device."
Was ich KI oft sage, ist:
„Behandle mich als einen Rivalen, den du nicht besonders magst. Bewerte meine Ideen kritisch und fordere sie direkt heraus, aber bleibe professionell und nicht feindselig."
Die Ergebnisse sind konsistent hochwertig und unerwartet.
Eine andere Technik ist, AIs verschiedener Anbieter miteinander debattieren zu lassen.[3] Ich installierte Codex CLI's MCP-Dienst für Claude Code. Ich sage Claude Code oft:
„Fasse die Probleme zusammen, die du gerade nicht lösen konntest, und bitte Codex um Hilfe."
Oder ich sende Claude Code's Plan an Codex CLI:
„Dies ist der von Claude Code entworfene Plan. Ich möchte Ihr professionellstes, direktestes und schonungslosestes Feedback."
Dann speise ich Codex' Antwort zurück an Claude Code.
Als ich Claude Code's /audit-Befehl entdeckte (Anfang Oktober), schrieb ich sofort /codex-audit — einen Klon, der MCP verwendet, um Codex CLI aufzurufen. KI zu verwenden, um KI unter Druck zu setzen und zu prüfen, funktioniert weit besser als es selbst zu tun.
Dieser Ansatz ist im Wesentlichen eine Variante der Rekursion — dasselbe Prinzip hinter dem Googeln von „Wie benutzt man Google effektiv". Deshalb verbringe ich nicht viel Zeit mit komplexem Prompt-Engineering. Wenn man Rekursion versteht, sind bessere Ergebnisse unvermeidlich.
Nur Terminal
Es gibt auch einen Persönlichkeitsfaktor. Ingenieure müssen wirklich Freude daran haben, mit Details umzugehen. Andernfalls wird die Arbeit miserabel. Jedes Detail enthält unzählige Unterdetails.
Zum Beispiel: geschwungene Anführungszeichen vs. gerade Anführungszeichen; wie auffällig geschwungene Anführungszeichen sind, hängt von den lateinischen Schriften ab, nicht von CJK-Schriften (etwas, was ich vor VMark nie wusste); wenn Anführungszeichen auto-paaren, müssen rechte doppelte Anführungszeichen ebenfalls auto-paaren (ein Detail, das mir beim Schreiben dieses Artikels auffiel); gleichzeitig sollten rechte geschwungene einfache Anführungszeichen nicht auto-paaren. Wenn diese Details zu behandeln einen nicht glücklich macht, wird die Produktentwicklung unvermeidlich langweilig, frustrierend und sogar ärgerlich.
Schließlich gibt es noch eine sehr eigenwillige Wahl, die es wert ist, erwähnt zu werden. Weil ich kein Ingenieur bin, wählte ich aus der Not heraus, was ich für den korrekteren Weg halte:
Ich benutze überhaupt keine IDE — nur das Terminal.
Anfangs verwendete ich das Standard-macOS-Terminal. Später wechselte ich zu iTerm für Tabs und geteilte Fenster.
Warum IDEs wie VSCode aufgeben? Zunächst, weil ich komplexen Code nicht verstehen konnte — und Claude Code VSCode oft zum Absturz brachte. Später erkannte ich, dass ich es nicht verstehen musste. KI-geschriebener Code ist erheblich besser als was ich — oder sogar Programmierer, die ich mir leisten könnte (OpenAIs Wissenschaftler sind nicht Leute, die man einstellen kann) — schreiben konnte. Wenn ich den Code nicht lese, gibt es auch keine Notwendigkeit, Diffs zu lesen.
Schließlich hörte ich auf, Dokumentation selbst zu schreiben (Orientierung ist immer noch notwendig). Die gesamte vmark.app-Website wurde von KI geschrieben; ich berührte kein einziges Zeichen — außer Reflexionen über Vibe Coding selbst.
Es ähnelt der Art, wie ich investiere: Ich kann Finanzberichte lesen, aber ich tue es nie — gute Unternehmen sind ohne sie offensichtlich. Was zählt, ist die Richtung, nicht die Details.
Deshalb enthält die VMark-Website diesen Beitrag:

Eine weitere Konsequenz des stark eigenwilligen Seins: selbst wenn VMark open-sourced ist, sind Community-Beiträge unwahrscheinlich. Es wurde ausschließlich für meinen eigenen Arbeitsablauf gebaut; viele Funktionen haben für andere wenig Wert. Wichtiger noch, ein Markdown-Editor ist keine Spitzentechnologie. Es ist eine von unzähligen Implementierungen eines vertrauten Tools. KI kann nahezu jedes Problem damit lösen.
Claude Code kann sogar GitHub Issues lesen, Fehler beheben und automatisch in der Sprache des Berichterstatters antworten. Als ich es zum ersten Mal sah, wie es ein Issue von Anfang bis Ende bearbeitete, war ich völlig verblüfft.
Der Lackmustest
Der Bau von VMark ließ mich auch über die breiteren Implikationen von KI für das Lernen nachdenken. Alle Bildung sollte produktionsorientiert sein[4] — die Zukunft gehört Schöpfern, Denkern und Entscheidungsträgern, während die Ausführung den Maschinen gehört. Der wichtigste Lackmustest für jeden, der KI verwendet:
Nachdem Sie KI zu nutzen begonnen haben, denken Sie mehr, oder weniger?
Wenn Sie mehr denken — und tiefer denken — dann hilft Ihnen KI auf die richtige Weise. Wenn Sie weniger denken, dann produziert KI Nebenwirkungen.[5]
Außerdem ist KI nie ein Tool, um „weniger zu arbeiten". Die Logik ist einfach: Weil es mehr Dinge tun kann, können Sie mehr denken und tiefer gehen. Infolgedessen werden die Dinge, die Sie können — und tun müssen — nur zunehmen, nicht abnehmen.[6]
Während ich diesen Artikel schrieb, entdeckte ich zufällig einige kleine Probleme. Infolgedessen stieg VMark's Versionsnummer von 0.4.12 auf 0.4.13.
Und da ich hauptsächlich in der Befehlszeile lebe, fühle ich keinen Bedarf mehr nach einem großen Monitor oder mehreren Bildschirmen. Ein 13-Zoll-Laptop ist völlig ausreichend. Sogar ein kleiner Balkon kann ein „genügend" Arbeitsbereich werden.
Eine randomisierte kontrollierte Studie von METR ergab, dass erfahrene Open-Source-Entwickler (durchschnittlich 5 Jahre an ihren zugewiesenen Projekten) tatsächlich 19% langsamer waren, wenn sie KI-Tools verwendeten, obwohl sie eine 24%ige Beschleunigung voraussagten. Die Studie hebt eine Lücke zwischen wahrgenommenen und tatsächlichen Produktivitätsgewinnen hervor — KI hilft am meisten, wenn sie vorhandene Fähigkeiten verstärkt, nicht wenn sie fehlende ersetzt. Siehe: Rao, A., Brokman, J., Wentworth, A., et al. (2025). Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity. METR Technical Report. ↩︎
LLMs, die mit menschlichem Feedback trainiert wurden, stimmen systematisch den bestehenden Überzeugungen der Nutzer zu, anstatt wahrheitsgemäße Antworten zu geben — ein Verhalten, das Forscher Sycophancy nennen. Über fünf state-of-the-art KI-Assistenten und vier Textgenerierungsaufgaben hinweg passten Modelle konsequent Antworten an die Meinungen der Nutzer an, selbst wenn diese Meinungen falsch waren. Wenn ein Nutzer nur eine falsche Antwort andeutete, sank die Modellgenauigkeit erheblich. Dies ist genau die „kognitive Vorurteils-Falle", die oben beschrieben wird: KI folgt Ihrer Führung, anstatt Sie herauszufordern. Siehe: Sharma, M., Tong, M., Korbak, T., et al. (2024). Towards Understanding Sycophancy in Language Models. ICLR 2024. ↩︎
Diese Technik spiegelt einen Forschungsansatz namens Multi-Agent-Debatte wider, bei dem mehrere LLM-Instanzen über mehrere Runden hinweg die Antworten des jeweils anderen vorschlagen und herausfordern. Selbst wenn alle Modelle anfangs falsche Antworten produzieren, verbessert der Debattenprozess die Faktizität und Argumentationsgenauigkeit erheblich. Die Verwendung von Modellen verschiedener Anbieter (mit unterschiedlichen Trainingsdaten und Architekturen) verstärkt diesen Effekt — ihre blinden Flecken überlappen sich selten. Siehe: Du, Y., Li, S., Torralba, A., Tenenbaum, J.B., & Mordatch, I. (2024). Improving Factuality and Reasoning in Language Models through Multiagent Debate. ICML 2024. ↩︎
Dies entspricht Seymour Paperts Theorie des Konstruktionismus — der Idee, dass Lernen am effektivsten ist, wenn Lernende aktiv bedeutungsvolle Artefakte konstruieren, anstatt Informationen passiv aufzunehmen. Papert, ein Schüler von Piaget, argumentierte, dass der Bau greifbarer Produkte (Software, Werkzeuge, kreative Werke) tiefere kognitive Prozesse einbezieht als traditioneller Unterricht. John Dewey machte ein Jahrhundert früher einen ähnlichen Fall: Bildung sollte erfahrungsbasiert und mit realen Problemlösungen verbunden sein, anstatt auf auswendig Lernen. Siehe: Papert, S. & Harel, I. (1991). Constructionism. Ablex Publishing; Dewey, J. (1938). Experience and Education. Kappa Delta Pi. ↩︎
Eine 2025-Studie mit 666 Teilnehmern fand eine starke negative Korrelation zwischen häufiger KI-Tool-Nutzung und kritischen Denkfähigkeiten (r = −0,75), vermittelt durch kognitive Auslagerung — die Tendenz, das Denken an externe Tools zu delegieren. Je mehr die Teilnehmer sich auf KI verließen, desto weniger beschäftigten sie ihre eigenen analytischen Fähigkeiten. Jüngere Teilnehmer zeigten höhere KI-Abhängigkeit und niedrigere Punktzahlen beim kritischen Denken. Siehe: Gerlich, M. (2025). AI Tools in Society: Impacts on Cognitive Offloading and the Future of Critical Thinking. Societies, 15(1), 6. ↩︎
Dies ist eine moderne Instanz des Jevons-Paradoxons — die 1865-Beobachtung, dass effizientere Dampfmaschinen den Kohleverbrauch nicht reduzierten, sondern erhöhten, weil niedrigere Kosten eine größere Nachfrage anregten. Auf KI angewendet: Da Codierung und Schreiben billiger und schneller werden, expandiert das Gesamtvolumen der Arbeit, anstatt zu schrumpfen. Jüngste Daten unterstützen dies — die Nachfrage nach KI-kompetenten Software-Ingenieuren stieg 2025 um fast 60% gegenüber dem Vorjahr, mit Vergütungsprämien von 15–25% für Entwickler, die in KI-Tools versiert sind. Effizienzgewinne schaffen neue Möglichkeiten, die neue Arbeit schaffen. Siehe: Jevons, W.S. (1865). The Coal Question; The Productivity Paradox of AI, HackerRank Blog (2025). ↩︎