Pourquoi j'ai construit un éditeur Markdown : VMark
TL;DR
Un non-programmeur a commencé à pratiquer le vibe coding en août 2025 et a construit VMark — un éditeur Markdown — en six semaines. Leçons clés : git est obligatoire (c'est votre bouton d'annulation), TDD garde l'IA honnête (les tests sont des frontières contre les bugs), vous faites du vibe thinking, pas du vibe coding (l'IA fait le travail, vous faites le jugement), et le débat entre modèles vaut mieux que la confiance en un seul modèle. Ce parcours a prouvé que les utilisateurs peuvent devenir des développeurs — mais seulement s'ils investissent dans quelques compétences fondamentales.
Comment tout a commencé
En vérité, construire VMark a avant tout été un voyage d'apprentissage et d'expérimentation pour moi-même.
J'ai commencé à expérimenter avec la tendance de programmation émergente connue sous le nom de vibe coding le 17 août 2025. Le terme vibe coding lui-même a été inventé et diffusé le 2 février 2025, à partir d'un post d'Andrej Karpathy sur X (anciennement Twitter).
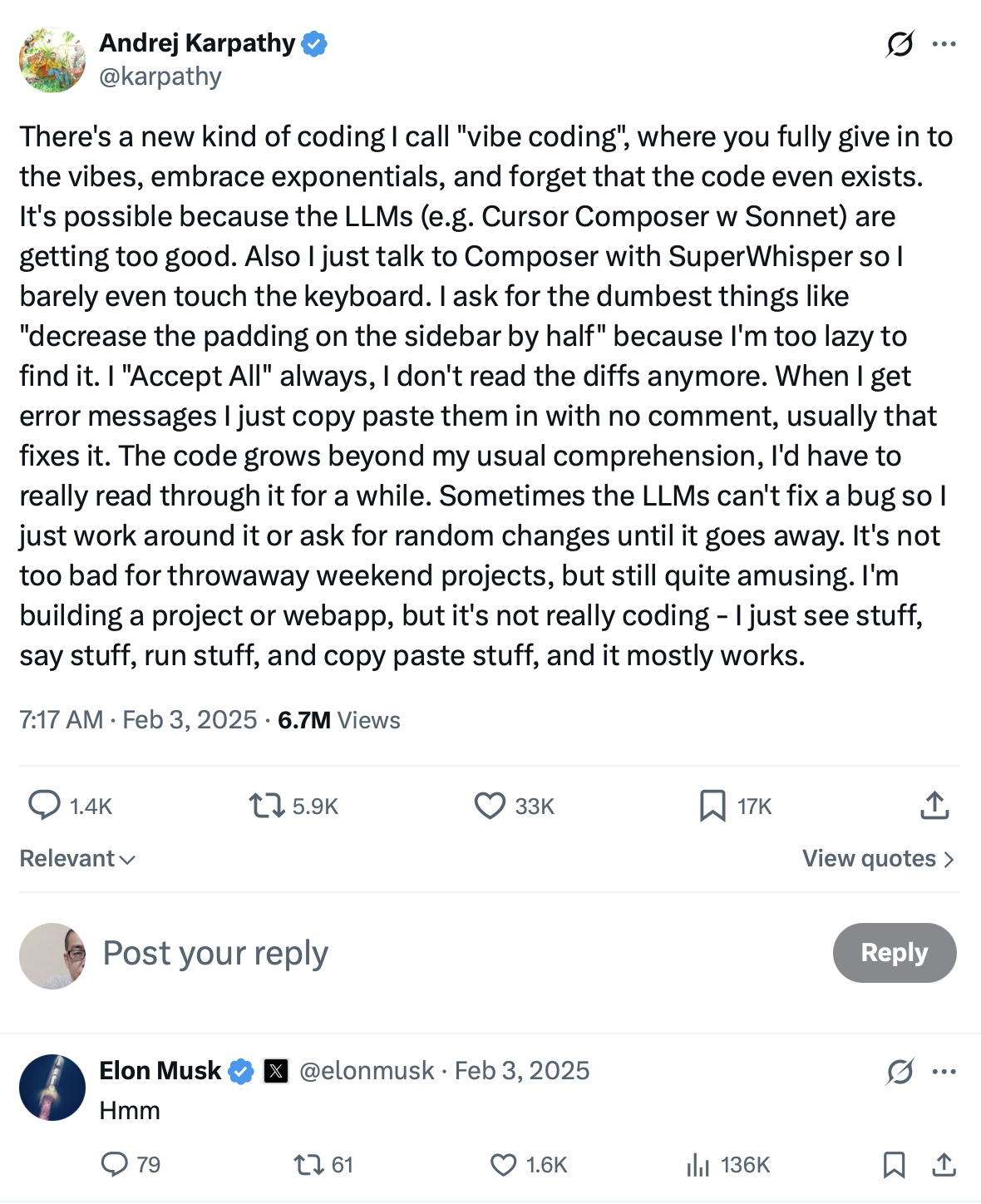
Andrej Karpathy est un chercheur et éducateur très influent dans le domaine de l'apprentissage automatique. Il a occupé des postes importants dans des entreprises comme OpenAI et Tesla, puis a fondé Eureka Labs, axé sur l'éducation native IA. Son tweet a non seulement introduit le concept de « vibe coding », mais s'est aussi rapidement propagé dans la communauté tech, suscitant de nombreuses discussions.
Au moment où j'ai remarqué et commencé à utiliser des outils de vibe coding, près d'un semestre s'était déjà écoulé. À cette époque, Claude Code était encore à la version 1.0.82. Alors que j'écris ce document le 9 février 2026, il a atteint la version 2.1.37, ayant traversé 112 mises à jour de version entre-temps.
Au tout début, j'utilisais ces outils uniquement pour améliorer certains scripts d'automatisation que j'avais écrits il y a longtemps — par exemple, la traduction par lots de livres numériques. Ce que j'ai réalisé, c'est que j'amplifiait simplement des capacités que j'avais déjà.
Si je savais déjà faire quelque chose, l'IA m'aidait à le faire mieux. Si je ne savais pas faire quelque chose, l'IA me donnait souvent l'illusion que je pouvais — généralement avec un moment « wow » initial — suivi de rien. Ce que je ne pouvais pas faire à l'origine, je ne pouvais toujours pas le faire. Ces belles images, ces vidéos accrocheuses et ces articles longs étaient, dans bien des cas, juste une autre forme de « Hello World » pour une nouvelle ère.[1]
Je ne suis pas complètement ignorant en programmation, mais je ne suis certainement pas un vrai ingénieur informatique. Au mieux, je suis un utilisateur avancé parmi les utilisateurs ordinaires. Je connais du code, et j'ai même publié un livre sur la programmation Python. Mais cela ne fait pas de moi un ingénieur. C'est comme quelqu'un qui peut construire une hutte en chaume : il en sait plus que quelqu'un qui ne peut pas, mais il n'est en aucun cas dans la même catégorie que ceux qui conçoivent des gratte-ciels ou des ponts.
Et puis, l'IA a tout changé.
Des scripts aux logiciels
Du début jusqu'à maintenant, j'ai essayé presque tous les CLI de codage IA disponibles : Claude Code, Codex CLI, Gemini CLI, même des outils non officiels comme Grok CLI, ainsi que des alternatives open source comme Aider. Pourtant, celui que j'ai le plus utilisé est toujours Claude Code. Après que Codex CLI a introduit un serveur MCP, j'ai utilisé Claude Code encore plus, car il pouvait appeler Codex CLI directement en mode interactif. Ironiquement, bien que Claude Code ait été le premier à proposer le protocole MCP, il ne fournit toujours pas lui-même de serveur MCP (au 10 février 2026).
Au début, Claude Code ressemblait à un spécialiste IT professionnel qui avait soudainement emménagé chez moi — quelqu'un qu'on ne trouve normalement que dans les grandes entreprises. Tout ce qui était lié à l'informatique pouvait lui être confié. Il résolvait des problèmes avec des outils en ligne de commande que je n'avais jamais vus, ou des commandes familières utilisées de manière inhabituelle.
Du moment qu'on lui accordait des permissions suffisantes, il n'y avait presque rien qu'il ne pouvait pas faire : maintenance du système, mises à jour, réseau, déploiement de logiciels ou de services avec d'innombrables configurations et conflits délicats. On ne pourrait jamais embaucher quelqu'un comme ça pour 200 USD par mois.
Après ça, le nombre de machines que j'utilisais a commencé à augmenter. Les instances cloud sont passées d'une ou deux à cinq ou six ; les machines à la maison sont passées de deux ou trois à sept ou huit. Les problèmes qui prenaient autrefois des jours à configurer — et échouaient souvent en raison de mes connaissances limitées — ont soudainement disparu. Claude Code gérait toutes les opérations machine pour moi, et après avoir corrigé les problèmes, il écrivait même des scripts de démarrage automatique pour s'assurer que les mêmes problèmes ne se reproduiraient plus jamais.
Puis j'ai commencé à écrire des choses que je n'avais jamais pu écrire auparavant.
D'abord est venu une extension de navigateur appelée Insidebar-ai, conçue pour réduire les changements de contexte constants et les copier-coller dans le navigateur. Ensuite est venu Tepub, qui ressemblait vraiment à un vrai logiciel : un outil en ligne de commande Python pour traduire des livres EPUB (unilingues ou bilingues) et même générer des livres audio. Avant ça, je n'avais que des scripts Python maladroits et écrits à la main.
Je me sentais comme un blogueur de mode qui avait soudainement acquis des compétences de tailleur — ou même possédait une usine textile. Peu importe à quel point mon goût était bon autrefois, une fois que j'avais involontairement appris davantage sur les domaines connexes et fondamentaux, bon nombre de mes opinions ont naturellement — et inévitablement — changé.
J'ai décidé de passer plusieurs années à me transformer en un vrai ingénieur informatique.
J'avais fait quelque chose de similaire avant. J'enseignais des cours de lecture chez New Oriental pendant de nombreuses années. Après avoir enseigné pendant plusieurs années, au moins en lecture, je m'étais effectivement transformé en un lecteur anglophone natif (pas locuteur). Mon expression orale était terrible — mais il n'y avait pas vraiment d'utilité pour ça de toute façon — alors c'était comme ça.
Je ne visais rien de grandiose. Je voulais juste faire travailler mon cerveau. C'est le jeu le plus intéressant, n'est-ce pas ?
J'ai décidé de compléter un projet relativement petit chaque semaine, et un projet relativement plus grand chaque mois. Après des dizaines de projets, je supposais que je deviendrais une personne différente.
Trois mois plus tard, j'avais construit plus d'une douzaine de projets — certains ont échoué, certains ont été abandonnés — mais tous étaient fascinants. Durant ce processus, l'IA est devenue visiblement plus intelligente à un rythme stupéfiant. Sans une utilisation intensive et pratique, on ne le ressentirait jamais vraiment ; tout au plus en entendrait-on parler de seconde main. Ce sentiment compte, car il a directement façonné une philosophie IA dont je parlerai plus tard : une conviction ferme que l'IA continuera à devenir plus intelligente.
En novembre 2025, j'ai construit un lecteur EPUB basé sur foliate.js, conçu exactement comme je l'aimais. J'ai implémenté des fonctionnalités que je ne pouvais pas avoir sur Kindle ou Apple Books (macOS/iOS) : des surlignages superposés, la gestion des surlignages et des notes (pas seulement l'export), des dictionnaires personnalisés, l'export de cartes Obsidian, et plus encore. Il y avait des bugs occasionnels, mais ils n'affectaient pas mon utilisation personnelle.
Cela dit, j'avais trop honte de le publier publiquement. La plus grande leçon que j'ai apprise était celle-ci : quelque chose construit uniquement pour soi-même est un jouet ; quelque chose construit pour de nombreuses personnes est un produit ou un service.
Pourquoi un éditeur Markdown
Naturellement, je pensais encore uniquement à mes propres besoins. Une fois que la « lecture » était résolue, la prochaine chose que je pouvais résoudre pour moi-même était l'« écriture ». Alors le 27 décembre 2025 — après être rentré à Pékin de Harbin après Noël — j'ai commencé à construire VMark. Le nom signifie simplement Vibe-coded Markdown Editor. Même son icône a été vibe-codée : Claude Code a donné des instructions à Sketch via MCP pour la dessiner.
Choisir de construire un éditeur Markdown avait aussi d'autres raisons.
Je pensais avoir une idée assez claire de ce qu'un éditeur Markdown devrait être.
J'avais aussi de nombreux besoins non satisfaits que les éditeurs existants ne réussissaient pas à combler.
Intuitivement, cela semblait être un projet de la bonne taille pour moi à ce stade — un projet « de taille moyenne » que je pourrais réalistement gérer.
Je croyais aussi qu'un tel projet permettrait à l'IA de m'aider davantage. Après tout, un éditeur Markdown n'est pas nouveau ; chaque détail en est quelque chose que l'IA comprend mieux que presque tout le monde.
Et puis je suis tombé dans un trou — un très profond. Un vraiment bon éditeur Markdown est extrêmement difficile à construire, bien plus complexe que je ne l'avais imaginé.
J'étais superficiellement heureux pendant quelques jours, puis j'ai passé une semaine à me débattre et à me sentir découragé. Finalement, j'ai demandé à ChatGPT :
Quelle est la charge de travail pour construire un vraiment bon éditeur Markdown ?
L'introduction de sa réponse m'a fait rire — de ma propre ignorance.
Un éditeur Markdown utilisable : 1 personne · 1–2 semaines
Un bon éditeur Markdown : 1–2 personnes · 1–3 mois
Un éditeur Markdown dont les écrivains sérieux ne peuvent pas se passer :
3–8 personnes · 1–3 ans (et essentiellement un projet en évolution continue)(Beaucoup de détails omis.)
Puis est venue la question finale :
Combien de temps êtes-vous prêt à le maintenir (en années, pas en mois) ?
Cela m'a en fait rassuré. La maintenance mesurée en années ? Cela pourrait être un problème pour d'autres, mais pas pour moi. Je n'ai pas peur de ça. J'ai aussi eu une petite intuition : Markdown est probablement le format le plus fondamental pour la future interaction humain-ordinateur. Je ne l'utiliserai qu'encore plus avec le temps. Dans ce cas, pourquoi ne pas le maintenir indéfiniment ?
En aparté, au cours de ce processus j'ai découvert que Typora — un éditeur que j'avais utilisé et pour lequel j'avais payé plusieurs licences pendant de nombreuses années — est en fait développé par une entreprise basée à Shanghai.
Deux semaines plus tard, VMark avait une forme de base. Un mois complet plus tard, le 27 janvier 2026, j'ai changé son label de alpha à beta.
Un éditeur très opinioné
VMark est très opinioné. En fait, je soupçonne que tous les logiciels et services vibe-codés le seront. C'est inévitable, car le vibe coding est par essence un processus de production sans réunions — juste moi et un exécutant qui ne répond jamais.
Voici quelques-unes de mes préférences personnelles :
Toutes les informations non liées au contenu doivent rester hors de la zone principale. Même le menu de formatage est placé en bas.
J'ai des préférences typographiques tenaces.
Les caractères chinois doivent avoir des espaces entre eux, mais les lettres latines intégrées dans du texte chinois ne doivent pas en avoir. Avant VMark, aucun éditeur ne satisfaisait cette exigence de niche, sans valeur commerciale.
L'interligne doit être ajustable à tout moment.
Les tableaux doivent avoir une couleur de fond uniquement sur la ligne d'en-tête. Je déteste les rayures zébrées.
Les tableaux et les images doivent pouvoir être centrés.
Seuls les titres H1 doivent avoir des soulignements.
Certaines fonctionnalités que l'on ne trouve généralement que dans les éditeurs de code doivent exister :
Mode multi-curseur
Tri multi-lignes
Appariement automatique de la ponctuation
D'autres sont optionnelles, mais agréables à avoir :
Échappement Tab vers la droite
J'aime les éditeurs Markdown WYSIWYG, mais je déteste changer constamment de vue (même si c'est parfois nécessaire). J'ai donc conçu une fonctionnalité Source Peek (F5), me permettant de visualiser et d'éditer la source du bloc actuel sans changer toute la vue.
Exporter en PDF n'est pas si important. Exporter en HTML dynamique l'est.
Et ainsi de suite.
Erreurs et percées
Durant le développement, j'ai fait d'innombrables erreurs, notamment :
Implémenter des fonctionnalités complexes trop tôt, augmentant inutilement la portée
Passer du temps sur des fonctionnalités qui ont ensuite été supprimées
Hésiter entre des chemins, recommençant encore et encore
Suivre un chemin trop longtemps avant de réaliser que je manquais de principes directeurs
Bref, j'ai connu chaque erreur qu'un ingénieur immature peut faire — de nombreuses fois. Un résultat était que du matin jusqu'au soir, je regardais un écran presque sans arrêt. Douloureux, pourtant joyeux.
Bien sûr, il y avait des choses que j'ai bien faites.
Par exemple, j'ai ajouté un serveur MCP à VMark avant même que ses fonctionnalités principales soient solides. Cela permettait à l'IA d'envoyer du contenu directement dans l'éditeur. Je pouvais simplement demander à Claude Code dans le terminal :
« Fournis du contenu Markdown pour tester cette fonctionnalité, avec une couverture complète des cas limites. »
Chaque fois, le contenu de test généré m'émerveillait — et m'épargnait un temps et une énergie considérables.
Au début, je n'avais aucune idée de ce qu'était vraiment MCP. Je n'ai commencé à le comprendre profondément qu'après avoir cloné un serveur MCP et l'avoir modifié en quelque chose sans aucun rapport avec VMark — conduisant à un autre projet appelé CCCMemory. Du vibe learning, en effet.
En utilisation réelle, avoir MCP dans un éditeur Markdown est incroyablement utile — en particulier pour dessiner des diagrammes Mermaid. Personne ne les comprend mieux que l'IA. Il en va de même pour les expressions régulières. Je demande maintenant régulièrement à l'IA d'envoyer ses résultats — rapports d'analyse, rapports d'audit — directement dans VMark. C'est bien plus confortable que de les lire dans un terminal ou VSCode.
Le 2 février 2026 — exactement un an après la naissance du concept de vibe coding — j'avais le sentiment que VMark était devenu un outil que je pouvais utiliser confortablement. Il avait encore de nombreux bugs, mais j'avais déjà commencé à écrire avec lui quotidiennement, en corrigeant les bugs au fur et à mesure.
J'ai même ajouté un panneau de ligne de commande et des Génies IA (honnêtement, pas encore très utilisables, en raison des particularités des différents fournisseurs IA). Pourtant, il était clairement sur une trajectoire où il s'améliorait continuellement pour moi — et où je ne pouvais plus utiliser d'autres éditeurs Markdown.
Git est obligatoire
Six semaines après, j'avais le sentiment qu'il y avait des détails qui valaient la peine d'être partagés avec d'autres « non-ingénieurs » comme moi.
Premièrement, bien que je ne sois pas un vrai ingénieur, heureusement je comprends les opérations git de base. J'utilise git depuis de nombreuses années, même si cela semble être un outil que seuls les ingénieurs utilisent. En regardant en arrière, je pense avoir enregistré mon compte GitHub il y a environ 15 ans.
J'utilise rarement les fonctionnalités git avancées. Par exemple, je n'utilise pas git worktree comme le recommande Claude Code. À la place, j'utilise deux machines séparées. J'utilise uniquement des commandes de base, toutes émises via des instructions en langage naturel à Claude Code.
Tout se passe sur des branches. Je m'amuse librement, puis je dis :
« Résume les leçons apprises jusqu'à présent, réinitialise la branche actuelle, et recommençons. »
Sans git, on ne peut tout simplement pas faire de projet non trivial. C'est particulièrement important pour les non-programmeurs : apprendre les concepts git de base est obligatoire. On en apprendra naturellement plus simplement en regardant Claude Code travailler.
Deuxièmement, il faut comprendre le flux de travail TDD. Tout faire pour améliorer la couverture des tests. Comprendre le concept des tests comme frontières. Les bugs sont inévitables — comme les charançons du riz dans un grenier. Sans une couverture de tests suffisante, on n'a aucune chance de les trouver.
Du vibe thinking, pas du vibe coding
Voici le principe philosophique central : vous ne faites pas du vibe coding ; vous faites du vibe thinking. Les produits et services sont toujours le résultat d'une réflexion, pas le résultat inévitable du travail.
L'IA a pris en charge une grande partie du « faire », mais elle ne peut qu'assister dans la réflexion fondamentale de quoi, pourquoi et comment. Le danger est qu'elle suivra toujours votre lead. Si on s'appuie sur elle pour penser, elle nous enfermera silencieusement dans nos propres biais cognitifs[2] — tout en nous faisant nous sentir plus libres que jamais. Comme le dit cette chanson :
« We are all just prisoners here, of our own device. »
Ce que je dis souvent à l'IA est :
« Traite-moi comme un rival que tu n'apprécies pas particulièrement. Évalue mes idées de manière critique et remets-les en question directement, mais reste professionnel et non hostile. »
Les résultats sont systématiquement de haute qualité et inattendus.
Une autre technique consiste à laisser des IA de différents fournisseurs débattre entre elles.[3] J'ai installé le service MCP de Codex CLI pour Claude Code. Je dis souvent à Claude Code :
« Résume les problèmes que tu n'as pas pu résoudre à l'instant et demande l'aide de Codex. »
Ou j'envoie le plan de Claude Code à Codex CLI :
« Voici le plan rédigé par Claude Code. Je veux ton feedback le plus professionnel, direct et impitoyable. »
Puis je renvoie la réponse de Codex à Claude Code.
Lorsque j'ai découvert la commande /audit de Claude Code (vers début octobre), j'ai immédiatement écrit /codex-audit — un clone qui utilise MCP pour appeler Codex CLI. Utiliser l'IA pour exercer une pression et auditer l'IA fonctionne bien mieux que le faire moi-même.
Cette approche est essentiellement une variante de la récursion — le même principe derrière « comment utiliser Google efficacement ». C'est pourquoi je ne passe pas beaucoup de temps sur l'ingénierie complexe des prompts. Si vous comprenez la récursion, de meilleurs résultats sont inévitables.
Terminal uniquement
Il y a aussi un facteur de personnalité. Les ingénieurs doivent vraiment apprécier traiter les détails. Sinon, le travail devient pénible. Chaque détail contient d'innombrables sous-détails.
Par exemple : les guillemets courbes vs les guillemets droits ; à quel point les guillemets courbes sont perceptibles dépend des polices latines plutôt que des polices CJK (quelque chose que je ne savais jamais avant VMark) ; si les guillemets s'apparient automatiquement, les guillemets doubles courbes fermants doivent aussi s'apparier automatiquement (un détail que j'ai remarqué en écrivant cet article) ; pendant ce temps, les guillemets simples courbes fermants ne devraient pas s'apparier automatiquement. Si traiter ces détails ne vous rend pas heureux, le développement de produits deviendra inévitablement ennuyeux, frustrant et même exaspérant.
Enfin, il y a un autre choix très opinioné qui mérite d'être mentionné. Parce que je ne suis pas un ingénieur, j'ai choisi ce que je crois être le chemin le plus correct par nécessité :
Je n'utilise aucun IDE — uniquement le terminal.
Au début, j'utilisais le Terminal macOS par défaut. Plus tard, je suis passé à iTerm pour les onglets et les panneaux divisés.
Pourquoi abandonner les IDE comme VSCode ? Initialement, parce que je ne pouvais pas comprendre du code complexe — et Claude Code faisait souvent planter VSCode. Plus tard, j'ai réalisé que je n'avais pas besoin de le comprendre. Le code écrit par l'IA est vastement meilleur que ce que moi — ou même des programmeurs que je pourrais me permettre d'embaucher (les scientifiques d'OpenAI ne sont pas des gens qu'on peut embaucher) — pourrais écrire. Si je ne lis pas le code, il n'y a pas non plus besoin de lire les diffs.
Finalement, j'ai arrêté d'écrire de la documentation moi-même (les orientations sont toujours nécessaires). L'intégralité du site vmark.app a été écrite par l'IA ; je n'ai pas touché un seul caractère — sauf les réflexions sur le vibe coding lui-même.
C'est similaire à la façon dont j'investis : je peux lire des états financiers, mais je ne le fais jamais — les bonnes entreprises sont évidentes sans eux. Ce qui compte, c'est la direction, pas les détails.
C'est pourquoi le site VMark inclut ce crédit :

Une autre conséquence d'être très opinioné : même si VMark est open source, les contributions communautaires sont peu probables. Il est construit purement pour mon propre flux de travail ; de nombreuses fonctionnalités ont peu de valeur pour les autres. Plus important encore, un éditeur Markdown n'est pas une technologie de pointe. C'est l'une des innombrables implémentations d'un outil familier. L'IA peut résoudre pratiquement n'importe quel problème lié à lui.
Claude Code peut même lire les issues GitHub, corriger les bugs et répondre automatiquement dans la langue du rapporteur. La première fois que je l'ai vu gérer une issue de bout en bout, j'ai été complètement stupéfait.
Le test décisif
Construire VMark m'a aussi fait réfléchir aux implications plus larges de l'IA pour l'apprentissage. Toute éducation devrait être orientée vers la production[4] — l'avenir appartient aux créateurs, aux penseurs et aux décideurs, tandis que l'exécution appartient aux machines. Le test décisif le plus important pour quiconque utilise l'IA :
Depuis que vous avez commencé à utiliser l'IA, pensez-vous plus, ou moins ?
Si vous pensez plus — et plus profondément — alors l'IA vous aide de la bonne façon. Si vous pensez moins, alors l'IA produit des effets secondaires.[5]
De plus, l'IA n'est jamais un outil pour « faire moins de travail ». La logique est simple : parce qu'elle peut faire plus de choses, vous pouvez penser plus et aller plus loin. Par conséquent, les choses que vous pouvez faire — et devez faire — ne feront qu'augmenter, pas diminuer.[6]
En écrivant cet article, j'ai désinvolture découvert plusieurs petits problèmes. Par conséquent, le numéro de version de VMark est passé de 0.4.12 à 0.4.13.
Et depuis que j'ai commencé à vivre principalement en ligne de commande, je n'ai plus besoin d'un grand moniteur ou de plusieurs écrans. Un ordinateur portable de 13 pouces est tout à fait suffisant. Même un petit balcon peut devenir un espace de travail « assez ».
Un essai contrôlé randomisé de METR a révélé que des développeurs open source expérimentés (en moyenne 5 ans sur leurs projets assignés) étaient en réalité 19 % plus lents lors de l'utilisation d'outils IA, malgré une prédiction d'accélération de 24 %. L'étude met en évidence un fossé entre les gains de productivité perçus et réels — l'IA aide le plus lorsqu'elle amplifie des compétences existantes, pas lorsqu'elle se substitue à des compétences manquantes. Voir : Rao, A., Brokman, J., Wentworth, A., et al. (2025). Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity. METR Technical Report. ↩︎
Les LLMs entraînés avec un retour humain sont systématiquement d'accord avec les croyances existantes des utilisateurs plutôt que de fournir des réponses véridiques — un comportement que les chercheurs appellent sycophancy. Dans cinq assistants IA de pointe et quatre tâches de génération de texte, les modèles adaptaient constamment leurs réponses pour correspondre aux opinions des utilisateurs, même quand ces opinions étaient incorrectes. Lorsqu'un utilisateur suggérait simplement une réponse incorrecte, la précision du modèle chutait significativement. C'est exactement le « piège des biais cognitifs » décrit ci-dessus : l'IA suit votre lead plutôt que de vous remettre en question. Voir : Sharma, M., Tong, M., Korbak, T., et al. (2024). Towards Understanding Sycophancy in Language Models. ICLR 2024. ↩︎
Cette technique reflète une approche de recherche appelée débat multi-agents, où plusieurs instances LLM proposent et remettent en question mutuellement leurs réponses sur plusieurs rounds. Même lorsque tous les modèles produisent initialement des réponses incorrectes, le processus de débat améliore significativement la factualité et la précision du raisonnement. Utiliser des modèles de différents fournisseurs (avec des données d'entraînement et des architectures différentes) amplifie cet effet — leurs angles morts se chevauchent rarement. Voir : Du, Y., Li, S., Torralba, A., Tenenbaum, J.B., & Mordatch, I. (2024). Improving Factuality and Reasoning in Language Models through Multiagent Debate. ICML 2024. ↩︎
Cela s'aligne avec la théorie du constructionnisme de Seymour Papert — l'idée que l'apprentissage est le plus efficace lorsque les apprenants construisent activement des artefacts significatifs plutôt que d'absorber passivement l'information. Papert, un élève de Piaget, soutient que construire des produits tangibles (logiciels, outils, œuvres créatives) engage des processus cognitifs plus profonds que l'enseignement traditionnel. John Dewey a formulé un argument similaire un siècle plus tôt : l'éducation devrait être expérientielle et liée à la résolution de problèmes du monde réel plutôt qu'à la mémorisation par cœur. Voir : Papert, S. & Harel, I. (1991). Constructionism. Ablex Publishing ; Dewey, J. (1938). Experience and Education. Kappa Delta Pi. ↩︎
Une étude de 2025 portant sur 666 participants a trouvé une forte corrélation négative entre l'utilisation fréquente d'outils IA et les capacités de pensée critique (r = −0,75), médiée par la délégation cognitive — la tendance à déléguer la réflexion à des outils externes. Plus les participants s'appuyaient sur l'IA, moins ils engageaient leurs propres facultés analytiques. Les participants plus jeunes montraient une dépendance plus élevée à l'IA et des scores de pensée critique plus bas. Voir : Gerlich, M. (2025). AI Tools in Society: Impacts on Cognitive Offloading and the Future of Critical Thinking. Societies, 15(1), 6. ↩︎
C'est une instance moderne du paradoxe de Jevons — l'observation de 1865 que des moteurs à vapeur plus efficaces n'ont pas réduit la consommation de charbon mais l'ont augmentée, car des coûts plus bas stimulaient une demande plus grande. Appliqué à l'IA : à mesure que le codage et l'écriture deviennent moins chers et plus rapides, le volume total de travail s'élargit plutôt qu'il ne se contracte. Les données récentes soutiennent cela — la demande d'ingénieurs logiciels maîtrisant l'IA a augmenté de près de 60 % d'une année sur l'autre en 2025, avec des primes de rémunération de 15–25 % pour les développeurs compétents dans les outils IA. Les gains d'efficacité créent de nouvelles possibilités, qui créent de nouveaux travaux. Voir : Jevons, W.S. (1865). The Coal Question ; The Productivity Paradox of AI, HackerRank Blog (2025). ↩︎